|
1. 选举用到的消息类型 在讲之前,咱们先看看选举会用到哪些消息,这些消息类型至关重要,可以把它们类比 raft 中 RequestVote RPC 传送的消息。 在“palf源码结构”中有讲(这个写了,但要整理下才能发), election_message.h 这个文件中定义了一些用于 RPC 的消息,所有选举执行时候需要用到的逻辑都基于这些消息类型,所以理解这些消息类型是至关重要的。在一次 basic paxos 流程中,一共会有如下几个步骤,每个步骤涉及到一种消息类型。 
图源不明图中一共有4个箭头,所以要实现选举,至少需要4种类型的消息,而 OceanBase 多了一个用于主节点主动让出权限的消息 ElectionChangeLeaderMsg,所以 OB 跟选举相关的消息类型一共有5种: class ElectionMsgBase { int64_t id_; // 消息ID,用于唯一标识一条消息 common::ObAddr sender_; // **发送者地址 common::ObAddr receiver_; // 接收者地址 int64_t restart_counter_; // 重启计数器,用于跟踪节点的重启次数 int64_t ballot_number_; // **提案编号, int64_t msg_type_; // 消息类型,用于标识消息的具体用途,如 PrepareRequest, PrepareResponse 等}
- 选举 prepare 请求以及回复(下面四类消息的具体内容,在后续每个步骤中会讲)
class ElectionPrepareRequestMsg : public ElectionMsgBase {};class ElectionPrepareResponseMsgMiddle : public ElectionMsgBase {}
class ElectionAcceptRequestMsg : public ElectionMsgBase {}class ElectionAcceptResponseMsg : public ElectionMsgBase {}
- Leader 变更:某个 Leader 想将租约转让给某个节点时,使用这个消息(这部分还未完全搞懂)
class ElectionChangeLeaderMsg : public ElectionMsgBase {}
后续关于选举的代码解析就从这几个消息类型依次展开
在看解析这之前,请务必搞清楚 Leader,Follower 与 proposer,acceptor 的关系 - 每个节点只能扮演 Leader 或者 Follower,这是选举选出来的结果。
- 每个节点同时扮演 proposer 和 acceptor,这是选举过程中, paxos 中的角色。
P1 - Prepare第一阶段-> ElectionPrepare这个阶段对应了 basic paxos 中的三个部分:第一个箭头的发出(send prepare request),第一个箭头的接收(get prepare request),以及第二个箭头的发出(send prepare response) OB代码中,proposer 在 prepare 阶段会向所有成员发送 prepare 请求,尝试获取大多数成员的同意。而每个节点在收到 prepare 请求后,需要根据这个请求执行一系列操作,比如返回拒绝或者同意消息。(如raft中每个follower只有一张选票,只投给日志项比新的等),简单来说,可以理解成一次尝试选举的开端。 除了 prepare 阶段会使用这个函数广播 prepare 请求,当 proposer 收到 prepare 请求并满足某些条件时,也会推大自己的 ballot_number 并广播 prepare 请求(不是直接使用这个函数),而这则是作者设计的选举算法中最关键的一个概念:“一呼百应”。 “一呼”指的便是这个 prepare 函数的执行,它可能会触发所有其它节点也广播 preapre request。 “百应”则是指上述收到 prepare 消息后自己也广播 prepare request 的操作。 一呼百应再加上后续的“时间窗口”这一个概念,让 OB 拥有了可以根据优先级选出Leader的这一重要特性,而 raft 是做不到这一点的。(这是整个算法中比较核心而又较为难懂的部分了,感谢作者在评论区的指点) 下面是 prepare 请求的消息类型,其中比较关键的变量是 role_,表示发送这条 prepare 消息的身份: Leader / Follower,接收者也会根据 role_ 做出不同的反应。(注意看,这里没有 candidate 这个概念。其实 Follower 发送 prepare 消息时就相当于是在参与竞选了,扮演的也就是 candidate 的成分。) class ElectionPrepareRequestMsgMiddle : public ElectionMsgBase { int64_t role_; // 节点的角色 (Leader, Follower,没有 candidate) bool is_buffer_valid_; // 选举优先级缓冲区是否有效 uint64_t inner_priority_seed_; // 选举优先级种子,用于计算选举优先级,每一个种子计算出来的所有节点的优先级是固定的,相当于提前分配好了节点的优先值。 LogConfigVersion membership_version_; // 当前日志配置的版本信息 unsigned char priority_buffer_[PRIORITY_BUFFER_SIZE]; // 选举优先级缓冲区,存储选举优先级};
-> send prepare request直接看函数实现:ElectionProposer::prepare(const ObRole role) src/logservice/palf/election/algorithm/election_proposer.cpp prepare 的整体逻辑: - 检查:如果自己是 Follower,且此次 prepare 与上一次的间隔太短(小于 “最大的一轮选的时间的一半”:10/2 = 5s),则放弃此次 prepare。
- 如果自己是 follower:也就是说自己作为 candidate 在参与选举,则需要将ballot_number推大为目前自己看到的最大的ballot_number +1。(不保真理解:同 raft 的任期一个道理,在当前选举轮次如果没能当选,则需要递增选举轮次号,进入下一轮选举轮次)
- 如果自己是 leader:不用推大 ballot_number。(不保真理解:从后续的逻辑来看,当 Leader 在租约内续租时,如果收到了更大 ballot_number 的回复,会在将自己的 ballot_number 更新为这个更大的number,并执行 prepare步骤,应该是为了保持自己在最新的选举轮次的同时,也呼唤其它节点保持在最新的选举轮次,并不是一次选举操作)
- 广播 PrepareRequest 请求。
对 ballot number 的理解:OB的注释称其为选举轮次,并且从它推大的逻辑来看,应该可以类比 raft 中的 term。 至于“最大的一轮选的时间的一半”这个值的设定,在注释中可以得到答案,简单来说,是对“一呼”和“百应”这两个操作同时发生时可能出现的问题的优化,不是特别核心。 // 通常情况下,所有副本的prepare定时任务都是被注册到相同的时间点执行的 // 即便一开始所有副本的定时任务的执行时间点不完全相同,“一呼百应”也会将这些定时任务同步到同一个时间点 //(因为进行一呼百应或者续lease成功后,应该重新计算下一次执行prepare定时任务的时间,这个计算和调整定时任务执行时间点的行为将会同步所有副本的prepare定时任务) // 上述行为是在设计里是妥当的,但会带来实现上的一个额外的并发问题: // 假如一个副本在同时收到了prepare消息,进行“百应”,同时它的prepare定时任务也被调度到了,要进行”一呼“ // 由于所有的“一呼”定时任务都是同步的,因此有很大概率碰到这个并发调度的问题 // 由于临界区的存在,两个操作是被串行化的,如果调度的顺序恰好是:先进行了“百应”,再进行“一呼” // 那么由于“一呼”要推大ballot number,这会中断当前的选举轮次 // 即便在“百应”动作后会重新调整下一次“一呼”动作的调度时间,但是这次重调整操作与当前正要执行的“一呼”动作仍然是并发的,无法保证调度顺序 // 所以这个逻辑仅靠定时任务是实现不了的,需要在用户执行定时任务的逻辑里作判断 // 这里引入last_do_prepare_ts_变量,来记录一个proposer上次执行“一呼”或者“百应”的时间点 // 下一次执行“一呼”或者“百应”动作的时间点距离上一次执行的时间点不应小于一个并发阈值
-> get prepare request同日志复制的 RPC 类似,PRC 的实现都从 src/logservice/palf/log_request_handler.cpp 内开始,一层一层经过函数调用直达最终的功能实现 LogRequestHandler::handle_request() ->PalfHandleImpl::handle_election_message() ->ElectionImpl::handle_message() 最终的实现逻辑落在了: handle_message(const ElectionPrepareRequestMsg &*msg*) src/logservice/palf/election/algorithm/election_impl.cpp 先看简化核心代码: int ElectionImpl::handle_message(const ElectionPrepareRequestMsg &msg){ // 互斥域,一个成员同时只能处理一条消息 bool need_register_devote_task = false; { LockGuard lock_guard(lock_); // 做为 proposer 的处理 if (msg.get_sender() != self_addr_) proposer_.on_prepare_request(msg, &need_register_devote_task); // 做为 acceptor 的处理 acceptor_.on_prepare_request(msg); // 如果 proposer 中,接收到了拥有更大 ballot_number 的请求, // 会在最后设置 need_register_devote_task 为 true // 这里将订阅一个 10s(最大可能的选举间隔) 后的 prepare task,至于为什么,暂不清楚 if (need_register_devote_task) proposer_.reschedule_or_register_prepare_task_after_(CALCULATE_MAX_ELECT_COST_TIME())))}
对于上述代码最后注册的 prepare_task,感谢作者在评论区给出了准确的解释:
“衡量选举算法,或者说衡量一切“类PAXOS协议”的两个基本点就是“正确性(correctness)”与“活性(liveness)”,对于一个强leader选举协议而言:正确性意味着,是否有唯一的leader而不会出现双主。活性意味着是否可以在多数派存活的任意的时刻都能有主。10s的时间设置就是为了防止在上一轮选举未结束前就开启下一轮选举从而中断选举过程(关于paxos的活锁lamport在<paxos made simple>中也有提及)” 可以看到在处理 prepare 消息时,同一个节点要担任两个身份,分别是 proposer 和 acceptor,同一条消息要同时在这两个身份下进行处理。它们的核心逻辑刚好对应了“百应”和“时间窗口”。 basic paxos 的流程中只有 acceptor 会处理 prepare 消息 proposer 的处理逻辑:ElectionProposer::on_prepare_request() - prepare 消息的 ballot_number 比自己小:回复拒绝
- 如果 ballot_number 与自己相同:直接忽略,不然会无限循环,不然会进入“一呼百应”的死循环。
- 如果 ballot_number 大于自己:将本机的选举轮次修改成这个更大的 ballot_number (不保真理解:这个地方的作用可以理解为:不管怎样,都要跟上当前最新的选举轮次,确保下次或者当前自己的选举轮次是最新的)
- 如果这个消息是 Leader 发的:不做任何处理,结束函数(不保真理解:走到这里的情况刚好对应了 prepare 步骤中 Leader 发送 prepare 的情况,只是为了让大家跟上选举轮次,而不触发选举)
- 否则:生成一个 prepare_request,广播给所有节点,也就是说,proposer 在收到一个具有更大选举轮次的 prepare_request 时,会增大自己的选举轮次,并重新发送 prepare request!(这里就是作者选举中核心的地方“一呼百应”中的百应,也就是当一个节点收到更新选举轮次的 prepare 消息时,自己也立即发送 prepare 消息,进行参选!但实际上这个操作并不一定会造成新的一轮选举并产生 Leader,比如大部分从节点的租约都没到期时,收到 prepare ok response 的节点并不会进入 accept 阶段)
acceptor 的处理逻辑:ElectionAcceptor::on_prepare_request() 来看 acceptor 具体的的逻辑之前,我先解释一下什么是时间窗口,时间窗口的概念非常重要,它主要由以下两个信息进行维护 - ballot_of_time_window_ :时间窗口开启时的选举轮次
- last_time_window_open_ts_:时间窗口开启时的时间戳
时间窗口是怎么做到让 OB 支持通过优先级选举出 Leader 的?以下是简化的步骤 - 每次acceptor收到一个新的选举轮次的 prepare 请求时,会打开一个时间窗口,也就是设置上述的两个信息。
- 后台会有一个定时任务,会在时间窗口关闭时执行,而时间窗口的生命长度为“两个消息最大往返延迟”。
- 在窗口开启的时候,对于收到的当前选举轮次的所有节点的 prepare 消息,保留优先级最高的那个。
- 时间窗口关闭之时,会对缓存的优先级最高的节点回复 ok 信息。
可以看到,通过时间窗口和之前的一呼百应,在大部分情况下,每个从节点在选举时,都能正确地向优先值最高的那个节点投票。至于“两个消息最大往返延迟”,仔细想一想即可以理解。 这里面 acceptor 并不会直接回复 ok 信息(投赞成票),而是通过维护时间窗口的 ballot_number 和到期时间来控制回复 ok 信息的时机。 再来看 acceptor 的具体逻辑 - 一个细节:对于一个刚启动的 acceptor,需要静默一段时间以维持 lease(租约)的语义
- prepare 消息的 ballot_number 比自己小:回复拒绝并结束。
- 如果收到的是 Leader 的 prepare 消息
- 直接无条件回应 ok
- 同时推大自己的 ballot number
- 同时,关闭时间窗口,结束。(不保真理解:走到这里的情况刚好对应了 prepare 步骤中 Leader 发送 prepare 的情况,只是为了让大家跟上选举轮次,而不触发选举)
- 如果prepare 消息的 ballot_number 比自己的大:需要关闭旧的时间窗口,并开启新的时间窗口,时间窗口的关闭时间如何设置,后面的注释讲的很清楚。(可以看到,如果收到更大的 ballot_number,并且时间窗口已经打开,就会先关掉旧的时间窗口,然后在这里重新打开,并为其设置新的 ballot_number。也就是说,上个时间窗口中收到的 prepare 消息还没来得及回复 ok,就被这个新的 prepare 消息覆盖了,应该也是一个优化,在短时间内任期号多次增长时有用)
- 在时间窗口内进行计票,保留当前选举轮次中优先级最大的 prepare 请求
// 当前Lease有效时,如果有效的时间超过一个最大单程消息延迟,则窗口关闭时机以Lease到期时间为准 // 否则视为普通的无主选举流程,窗口需要覆盖两个最大单程消息延迟
-> send prepare response很明显,返回的逻辑其实在上述 acceptor 接收 PrepareRequest 时实现了,所以这个阶段不用单独再拎出来解释了。
P2 - Prepare第二阶段-> ElectionPrepareResponse这个阶段对应了 basic paxos 图中的第二个箭头的接收(get prepare response),以及第三个箭头的发出(send accept request)。 对应到 paxos 中,proposer 检查自己的选票信息,如果获得了大部分选票,则发送 accept 操作试图让其它成员接收 propose。这个阶段就在干这事儿。 下面是 prepare 回复的消息类型。这里的租约非常关键,租约是 Leader 权限的抽象,涉及到两个关键信息:租约持有者和租约到期时间,持有则即是 Leader。每个节点都存储了一个租约信息(新节点除外) class ElectionPrepareResponseMsg: public ElectionMsgBase { bool accepted_; // 请求是否被接受 Lease lease_; // 租约,可能为空,持有租约的人相当于 Leader ElectionMsgDebugTs request_debug_ts_; // 请求的调试时间戳,用于调试}
-> get prepare response同上述步骤的代码调用栈一样,逻辑的实现最终都落到了ElectionImpl::handle_message()中,对不同的消息类型进行了不同的处理逻辑,算是多态的一种应用。 LogRequestHandler::handle_request() ->PalfHandleImpl::handle_election_message() ->ElectionImpl::handle_message() handle_message(const ElectionPrepareResponseMsg &msg) src/logservice/palf/election/algorithm/election_impl.cpp 这个函数处理比 prepare 简单多了,直接调用 proposer 的处理逻辑即可,accptor 无需理会。 proposer_.on_prepare_response(msg);
直接看 proposer 的处理逻辑:ElectionProposer::on_prepare_response() - 检查消息的有效性(check_ballot_and_restart_counter_valid_and_accepted())
- 如果消息的 ballot_number 比自己的小,则判定为过时消息,抛弃
- 如果消息的 ballot_number 更大,更新自己的 ballot_number为它
- 若自己是leader,触发leader prepare(为什么在任期间会收到拥有更大 ballot_number 的回复?)
- 检查是否具备进入accept阶段的四种情况:
- 对方目前没有lease,新成员会出现这种情况(这里的 lease 就是所谓的租约,也就是相当于一个身为领导才能有的发言,而租约时长对应的是lease_interval,从这里可以看出,如果大部分从节持有 Leader 的 lease 没有到期时,并不会选出一个新的 Leader)
- lease 是自己的
- lease 是切主源头的(有一个 Leader 将自己的位置让给了它)
- Lease 的 ballot_number 太旧
- 记录应答,判断现在的计数是否达到了多数派
- 刚好多数派时:进入 accept 阶段:调用 propose()函数, 生成 AcceptRequest 消息,并广播到所有节点。
对于 propose() 函数,可以抽象地看作是租约续租的操作,它在下列情况下会用到: - 选举阶段,一个节点收到大部分选票时,通过续租,让其它节点对于Leader的租约达成共识
- Leader 阶段,通过定期地执行 propose,实现续租
-> send accept request同理,这部分逻辑其实在上述对 prepare response 消息的处理中就实现了。
A1 - Accept 第一阶段-> ElectionAcceptRequest这个阶段对应了 paxos 中第三根箭头的接收(get accept request),第四根箭头的发起(send accept response) 下面是 accept request 消息类型,这里的lease_interval_异常关键,表示整个租约的时长。从节点需要依靠这个租约间隔更新租约到期时长,而更新租约需要非常小心才能维持 lease 和整个算法语义的正确性。 class ElectionAcceptRequestMsgMiddle : public ElectionMsgBase { int64_t lease_start_ts_on_proposer_; // 提议者上的租约开始时间戳 int64_t lease_interval_; // 租约间隔 LogConfigVersion membership_version_; // 成员关系版本}
更新租约的具体方式可以这样形容 - 从节点用“收到续租消息的时间点”+“lease_interval_”,即可得到它承认的 lease 到期时间点。
- 主节点收到大部分从节点的回复时,会将自己的租约到期时间点更新为“自己发出续租广播的时间点”+“lease_interval_”
可以发现,即使所有节点的物理时间点都不一致的情况下,从节点承认的 lease 到期时长都是从他们接收到消息开始计算的,加上同样长度的 lease_interval_后 ,肯定会比 Leader 自己承认的租约后到期(至少会多出一个消息传播的延迟) 接下来看代码实现 -> get accept request函数调用栈就不再赘述了,最后还是进入这个接口函数,下面先看简化代码 int ElectionImpl::handle_message(const ElectionAcceptRequestMsg &msg){ // 互斥域,一个acceptor同时只能处理一条Accept消息 { LockGuard lock_guard(lock_); // 推大 proposer 的选举轮次,保证下次选举的选举轮次是新的 if (msg.get_ballot_number() > proposer_.ballot_number_) proposer_.advance_ballot_number_and_reset_related_states_(msg.get_ballot_number(), "receive bigger accept request"); // acceptor 处理逻辑 acceptor_.on_accept_request(msg, &us_to_expired); } if ( // 定时:proposser 在租约到期前一秒,执行 prepare 操作 // 只允许 Follower 做这样的主动定时 prepare,Leader 只能被动触发 Prepare。proposer_.reschedule_or_register_prepare_task_after_(us_to_expired - CALCULATE_TRIGGER_ELECT_WATER_MARK())}
AcceptRequest 不需要由 proposer 执行对应的逻辑,所以直接走 acceptor 的函数即可 直接看 acceptor 的处理逻辑:ElectionAcceptor::on_accept_request() - 如果 AcceptRequest 的选举轮次(ballot_numer)比自己的小,回复拒绝消息
- 推大ballot number,防止accept lease的 ballot number 回退
- 更新 Lease (更新的方式如上述所说,可见下方简化代码)
- 通过 AcceptResponse 消息恢复 ok!
// 从节点更新 lease 到期时间点的方式lease_end_ts_ = max(lease_end_ts_, get_monotonic_ts() + accept_req.get_lease_interval());
-> send accept response同理,逻辑在上方已经实现了。 A2 - Accept 第二阶段-> ElectionAcceptResponse这个阶段对应了 paxos 中第四根箭头的接收,是选出 Leader 的最终步骤(get accept response) class ElectionAcceptResponseMsgMiddle : public ElectionMsgBase { int64_t lease_started_ts_on_proposer_; // 提议者上的租约开始时间戳 int64_t lease_interval_; // 租约间隔 int64_t process_request_ts_; // 处理请求的时间戳,Leader用于计算自己租约到期的时间 bool accepted_; // 请求是否被接受 bool is_buffer_valid_; // 优先级缓冲区是否有效 uint64_t inner_priority_seed_; // 内部优先级种子 LogConfigVersion responsed_membership_version_; // 响应中的成员关系版本 LogConfigVersion membership_version_; // 成员关系版本 unsigned char priority_buffer_[PRIORITY_BUFFER_SIZE]; // 优先级缓冲区,用于存储优先级信息}
这个消息中的 lease_started_ts_on_proposer_非常关键,主节点需要从所有 ok 消息中选出一个合理的,大部分人认可的租约到期时间戳做为自己的租约到期时间。 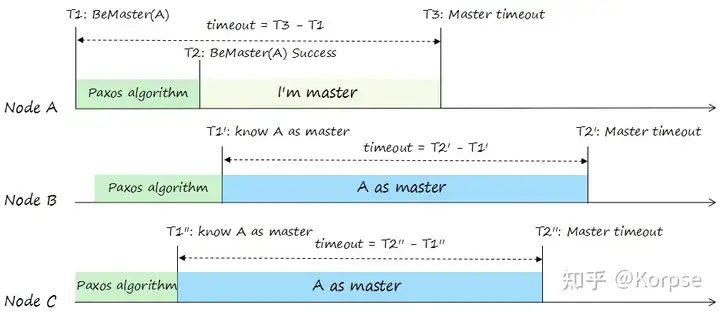
-> get accept response同 Prepare 第二阶段一样,调用栈比较简单,实现逻辑都在这个函数: Proposer 的处理逻辑:ElectionProposer::on_accept_response() - 检查消息的有效性(check_ballot_and_restart_counter_valid_and_accepted())
- 如果消息的 ballot_number 比自己的小,则判定为过时消息,抛弃
- 如果消息的 ballot_number 更大,更新自己的 ballot_number为它
- 若自己仍然是leader,触发leader prepare(这里的逻辑其实和 on_prepare_response() 第一步一样)
- 处理 AcceptResponse 消息:这里背地里做了非常关键的工作
- Proposer 中保存了一个数组,数组中存储了每个成员承认的租约到期时间,对于每个 ok 应答,都需要更新其发送节点对应的租约到期时间。
- 为什么:Leader 需要收集这些租约到期时间,用于寻找一个“大部分成员达成共识的,最久租约到期时间戳”
- 怎么算:每个成员返回的 AcceptResponse 中存储了lease_started_ts_on_proposer_ 这一关键变量,表示这个成员接收的续租消息的发出时间点,这个时间点是 Leader 自己的时间点。用 lease_started_ts_on_proposer_ + lease_interval 就可以得到一个安全的从节点承认的租约到期时间点。
- 判断是否达到多数派:
- 未达到多数派,不做操作
- 超过了多数派,依旧进入 c 流程,因为每个 Accept ok 都可能延长Leader的租约到期时间
- 刚好多数派:进入 accept 阶段:propose()
- 重新计算自己的租约到期时间戳
- 对上述步骤中维护的到期时间数组按照从高到低进行排序,并取第 (n/2)+1 个时间戳做为自己新的租约到期时间戳。也就是选出了上面说的 “大部分成员达成共识的,最久租约到期时间戳”(这里要好好品一下)
- 如果当前lease已经失效,中间可能出现过其他的leader,而本副本还未感知,需要先卸任
- 更新lease和允许成员变更的版本号:set_lease_and_epoch_if_lease_expired_or_just_set_lease()
- 如果自己是 Follower,则需要上任,上任的方式,则是以 Leader 的身份向所有节点广播 accept 消息,记得节点收到这种消息的反应吗:无条件更新 lease,也就实现了承认当前节点为主节点的功能。
- 如果发送消息的 Follower 优先级大于自己,尝试触发切主切主
- 具体实现是向切主对象发送一条 ElectionChangeLeaderMsg
- 切主对象收到这条消息后,需要进行一个 Leader prepare 流程。
-> 关于续约:Proposer 启动时,会注册两个定时任务:第一个用于定时 prepare,第二个用于续约,续约周期固定为消息延迟的一半,最大不超过250ms int ElectionProposer::start(){ reschedule_or_register_prepare_task_after_(3_s) register_renew_lease_task_()}
只有 Leader 会执行续约操作,而续约实际上就是调用 proposser::propose() 函数,广播 AcceptRequest,这也可以类比心跳。
| 

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2023-12-28 18:08:17
发表于 2023-12-28 18:08:17
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡